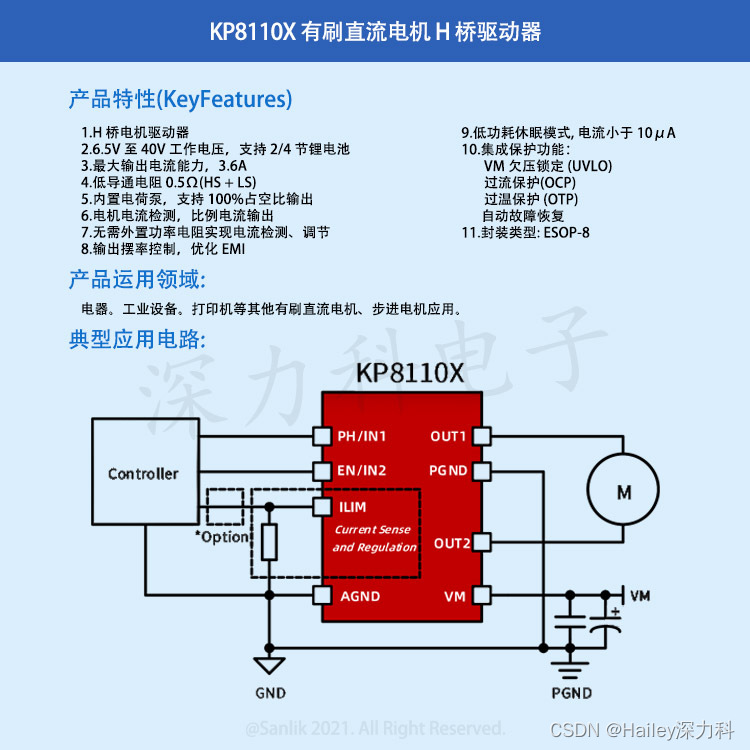
Debezium日常分享系列之:Debezium 2.7.0.Alpha2发布
- 新功能和改进
- 1.Oracle ROW_ID 包含在更改事件中
- 2.带有 JDBC 接收器的 PostreSQL 数组
- 3.Oracle 使用自定义模式名称刷新表
- 4.使用 JWT/seed 进行 NATS 身份验证
- 5.Oracle 大量表查询过滤器
新功能和改进
1.Oracle ROW_ID 包含在更改事件中
- 虽然 ROW_ID 在表的生命周期中在表的所有行中并不是唯一的,但它可以在以非常严格的方式管理表和行的生命周期的某些情况下使用。应社区的要求,我们在 Oracle 连接器的更改事件源信息块中添加了新的 row_id 字段。在以下条件下,此新字段将填充 ROW_ID 值:
- 仅从插入、更新和删除的流事件填充。
- 快照 evnet 将不包含 row_id 值。
- 仅由 LogMiner 和 XStream 流适配器提供,不支持 OpenLogReplicator。
任何不符合条件的事件都不会包含 row_id 字段,因为它被标记为可选。
2.带有 JDBC 接收器的 PostreSQL 数组
- JDBC 接收器连接器支持使用将源列映射到基于 Kafka ARRAY 的有效负载字段类型。借助 Debezium 2.7,您现在可以将基于 ARRAY 的字段序列化到目标 PostgreSQL 数据库,而无需更改配置。新的支持应该是完全透明的。
3.Oracle 使用自定义模式名称刷新表
- 在 Debezium 的早期版本中,Oracle 连接器经过严格设计,在连接器用户帐户的默认表空间中创建 LogMiner 刷新表。在用户的默认表空间可能不是理想目标并且 DBA 希望该表存在于单独的表空间中的情况下,这并不总是有用。
- 以前,用户需要修改用户帐户或使用具有正确表空间的新用户才能在正确的表空间位置创建表。在 Debezium 2.7 中,不再需要这样做,您可以安全地将目标模式/表空间的名称包含在配置中。
使用自定义架构名称的示例:
log.mining.flush.table.name=THE_OTHER_SCHEMA.LOG_MINING_FLUSH_TABLE
架构名称是可选的,如果未提供,连接器将继续使用相同的旧行为,即创建刷新表并检查其是否存在于用户的默认表空间中。
4.使用 JWT/seed 进行 NATS 身份验证
- Debezium Server NAT 流接收器适配器得到改进,支持基于 JWT/种子的身份验证。要开始使用 JWT/基于种子的身份验证,请在配置中提供以下必要值:
JWT 身份验证示例
debezium.sink.nats-jetstream.auth.jwt=<your_jwt_token>
种子认证示例
debezium.sink.nats-jetstream.auth.seed=<your_nkey_seed>
5.Oracle 大量表查询过滤器
Debezium Oracle 连接器可以在单个连接器部署中轻松支持数千个表;但是,您可能发现您想要使用 IN 模式自定义查询过滤器。此模式用于以下情况:您可能对其他表进行大量更改,并且希望在将更改传递到 Debezium 进行处理之前在数据库级别过滤掉该数据集。
在早期版本中,用户可能已经注意到,将 log.mining.query.filter.mode 设置为 in 值并且表包含列表包含超过 1000 个元素会生成 SQL 错误。 Oracle 不允许子句中包含超过 1000 个元素;然而,Debezium 2.7 通过在包含 1000 个项目内条款列表的多个存储桶之间使用析取来解决此限制。